發(fā)布時(shí)間:2018-03-31
欄目:教程中心
前面學(xué)習(xí)了隱藏列表頁(欄目頁)抓包分析教程,但有時(shí)列表頁沒有分頁號(hào)并且是動(dòng)態(tài)加載,本教程講解怎么采集這種列表頁
本教程所使用到的天線貓軟件有:文章組合工具集 萬能文章采集器
抓包工具:
抓包可選傲游瀏覽器或其他谷歌內(nèi)核瀏覽器或任何抓包工具。
抓包時(shí)注意,在網(wǎng)頁上鼠標(biāo)右鍵-審查-網(wǎng)絡(luò)(Network)才能進(jìn)入抓包界面:
網(wǎng)頁的訪問方法(Method):有GET和POST兩種,GET就是【一條網(wǎng)址】,而POST是【一條網(wǎng)址+投遞參數(shù)】,一般都是GET方法,但是如果抓包列表頁地址時(shí)碰到POST方法(比如百度百科)就需要特殊處理下才能使用到軟件上進(jìn)行采集
抓包過程:
以今日頭條為例,使用天線貓萬能文章采集器等多款軟件輔助
1、開始抓包:
當(dāng)下拉滾動(dòng)條到底部時(shí),該網(wǎng)頁就會(huì)刷新出新的新聞列表,通常抓包會(huì)抓到很多地址,可以通過響應(yīng)正文(Response)是否包含目標(biāo)內(nèi)容(如列表頁中的文章標(biāo)題、文章地址)、響應(yīng)內(nèi)容的大小(一般注意大尺寸)來判斷哪個(gè)才是新聞列表的刷新讀取地址(后面簡稱刷新地址)。
我這里抓包到的刷新地址是:http://toutiao.com/api/article/recent/?...
復(fù)制刷新地址的方法
可以右鍵單擊抓包列表中的刷新地址彈出菜單-Copy Link Address
或者左鍵單擊刷新地址Headers-General-Request URL-選中地址-右鍵菜單-復(fù)制
然后繼續(xù)抓下一個(gè)的刷新地址:http://toutiao.com/api/article/recent/?...
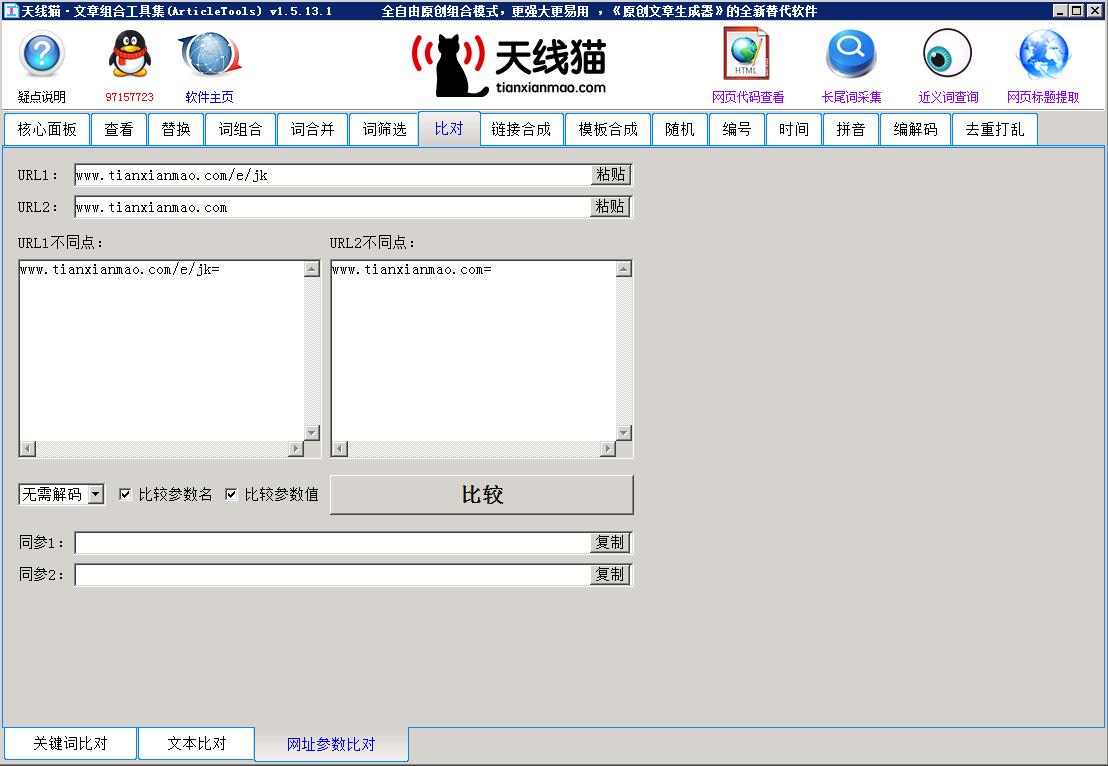
使用天線貓文章組合工具集比對(duì)-網(wǎng)址參數(shù)比對(duì)比較這2個(gè)刷新地址,可以發(fā)現(xiàn)有3個(gè)參數(shù)產(chǎn)生了變化。
2、分析抓包數(shù)據(jù):
在抓包時(shí)可以發(fā)現(xiàn)新聞列表的響應(yīng)正文是JSON數(shù)據(jù),因此使用天線貓Json解析助手來分析這3個(gè)參數(shù)是怎么來的:
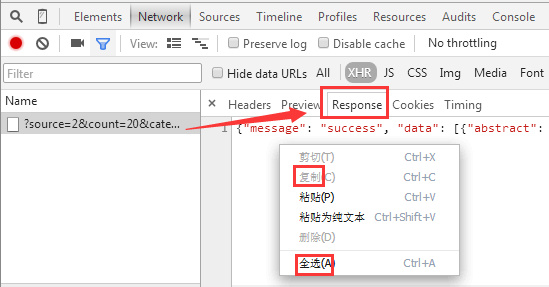
復(fù)制響應(yīng)正文的方法
可以右鍵單擊抓包列表中的刷新地址彈出菜單-CopyResponse
或者左鍵單擊刷新地址Response-右鍵菜單-全選-復(fù)制
可以看到,Json數(shù)據(jù)中的 next.max_behot_time 節(jié)點(diǎn)的值構(gòu)成了刷新地址中的第一個(gè) max_behot_time 參數(shù)
而Json數(shù)據(jù)中的 data.[15].create_time 節(jié)點(diǎn)(也就是新聞列表中的最后一個(gè)即序號(hào)為15的項(xiàng)目的 create_time)的值構(gòu)成了刷新地址中的第二個(gè) max_create_time 參數(shù)
而第三個(gè) _ 參數(shù)我們可以使用一個(gè)動(dòng)態(tài)時(shí)間戳(實(shí)際上這個(gè)參數(shù)沒什么作用,可以保留抓包時(shí)的原值,也可以使用一個(gè)動(dòng)態(tài)值)。
結(jié)果構(gòu)建出來的模板刷新地址:http://toutiao.com/api/article/recent/?source=2&count=15&category=__all__&max_behot_time=[#next.max_behot_time#]&utm_source=toutiao&offset=0&max_create_time=[#data.[15].create_time#]&_={#毫秒時(shí)間戳#}
然后發(fā)現(xiàn)這個(gè)今日頭條還要求提供Cookies,否則抓取到的新聞列表就不準(zhǔn)確,因此在抓包時(shí)可以到請(qǐng)求里復(fù)制出Cookies:uuid="w:2336ce5e12794f1c9d90ea07c2d4dc47"; tt_webid=19421740959; csrftoken=19f08b2051f0abbb85ee449e648fb3ad; CNZZDATA1258609184=1681606143-1466332000-%7C1466337400; _ga=GA1.2.451981020.1466332236; utm_source=toutiao
3、最后采集列表頁:
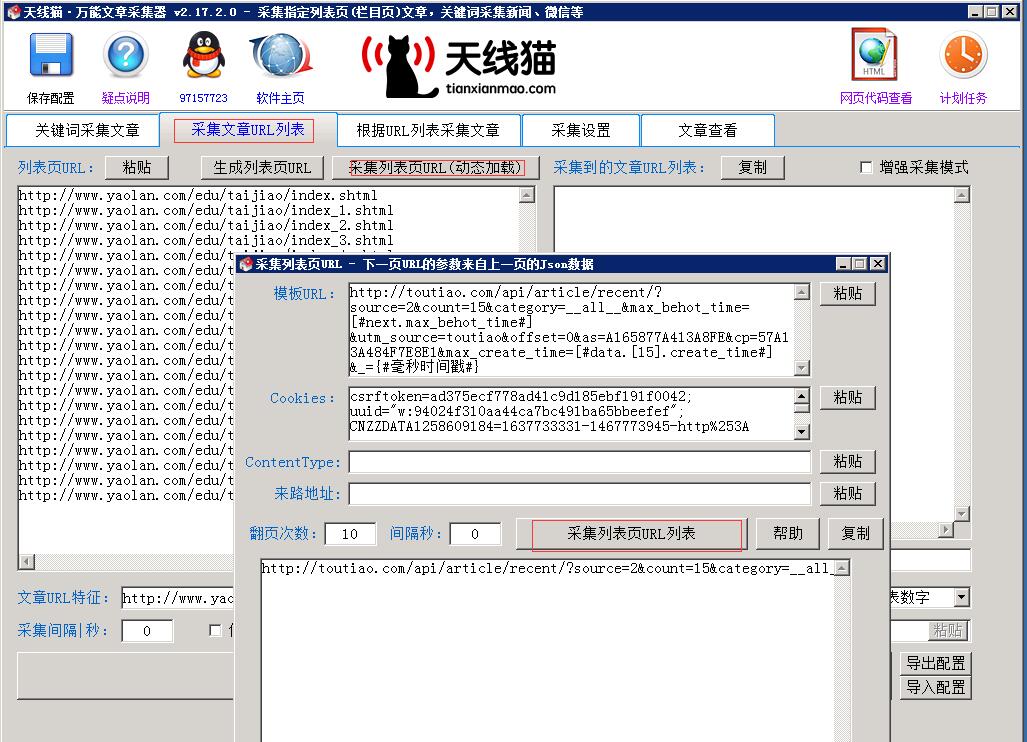
采集好列表頁后,在萬能文章采集器的【采集文章URL列表】對(duì)這些列表頁采集出文章地址列表時(shí),請(qǐng)保持【采集列表頁URL(動(dòng)態(tài)加載)】窗口處于打開狀態(tài),這樣才能調(diào)用該窗口中的Cookies設(shè)置,因?yàn)榻袢疹^條刷新新聞列表時(shí)要求Cookies。
下面是采集文章地址的設(shè)置:
上一篇:如何提交百度網(wǎng)址
文章地址:http://www.meyanliao.com/course/1045.html